API
Here we describe all the functions used to collapse the spectral cube which are typically called by the command line interface. However, importing these into your workflow may be useful.
In general, for the generated moment maps, MX, where X is an integer
denotes a statistical moment. For the non-traditional methods, v0, dV
and Fnu represent the line center, width and peak, respectively.
Note
The convolution for smooththreshold is currently experimental and is
work in progress. If things look suspicious, please raise an issue.
Note
Most collapse_* functions accept an optional acf keyword. When
supplied, the uncertainty maps are propagated through the full spectral
noise covariance 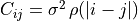 rather than
its diagonal, correctly accounting for channel-to-channel noise
correlation (e.g. from Hanning smoothing in the imaging pipeline). The
ACF can be estimated directly from the cube with
rather than
its diagonal, correctly accounting for channel-to-channel noise
correlation (e.g. from Hanning smoothing in the imaging pipeline). The
ACF can be estimated directly from the cube with
bettermoments.estimate_spectral_acf(), or enabled from the command
line with the --acf flag. Only the uncertainty maps are affected — the
moment values themselves are unchanged.
Moment Maps
Implementation of traditional moment-map methods. See the CASA documentation for more information.
- bettermoments.methods.collapse_zeroth(velax, data, rms, acf=None)
Collapses the cube by integrating along the spectral axis. It will return the integrated intensity along the spectral axis,
M0, and the associated uncertainty,dM0. Following Teague (2019) these are calculated by,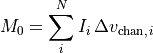
and
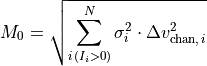
where
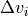 and
and 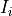 are the chanenl width and flux
density at the
are the chanenl width and flux
density at the 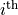 channel, respectively and the sum goes
over the whole
channel, respectively and the sum goes
over the whole axis.If
acfis provided, the uncertainty is propagated through the full spectral covariance matrix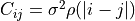 rather than its diagonal,
correctly accounting for noise correlation between channels (e.g.from
Hanning smoothing). See
rather than its diagonal,
correctly accounting for noise correlation between channels (e.g.from
Hanning smoothing). See bettermoments.estimate_spectral_acf().- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Flux densities or brightness temperature array. Assumes that the first axis is the velocity axis.
rms (float) – Noise per pixel in same units as
data.acf (Optional[ndarray]) – Normalised spectral ACF, e.g.from
bettermoments.estimate_spectral_acf(). IfNone(default), channels are assumed independent.
- Returns:
M0, the integrated intensity along provided axis anddM0, the uncertainty onM0in the same units asM0.- Return type:
M0(ndarray),dM0(ndarray)
- bettermoments.methods.collapse_first(velax, data, rms, acf=None)
Collapses the cube using the intensity weighted average velocity (or first moment map). For a symmetric line profile this will be the line center, however for highly non-symmetric line profiles, this will not give a meaningful result. Following Teague (2019), the line center is given by,
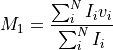
where
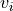 and are the velocity and flux density at the
channel, respectively and the sum goes over the whole
and are the velocity and flux density at the
channel, respectively and the sum goes over the whole
axis. In addition, the uncertainty is given by,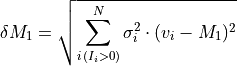
where
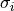 is the rms noise.
is the rms noise.If
acfis provided, the uncertainty is propagated through the full spectral covariance rather than its diagonal — seecollapse_zeroth().- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Flux densities or brightness temperature array. Assumes that the zeroth axis is the velocity axis.
rms (float) – Noise per pixel in same units as
data.acf (Optional[ndarray]) – Normalised spectral ACF. If
None(default), channels are assumed independent.
- Returns:
M1, the intensity weighted average velocity in units ofvelaxanddM1, the uncertainty in the intensity weighted average velocity with same units asv0.- Return type:
M1(ndarray),dM1(ndarray)
- bettermoments.methods.collapse_second(velax, data, rms, acf=None)
Collapses the cube using the intensity-weighted average velocity dispersion (or second moment). For a symmetric line profile this will be a measure of the line width. Following Teague (2019) this is calculated by,
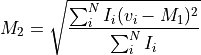
where
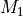 is the first moment and and are
the velocity and flux density at the channel,
respectively. The uncertainty is given by,
is the first moment and and are
the velocity and flux density at the channel,
respectively. The uncertainty is given by,![\delta M_2 &= \frac{1}{2 M_2} \cdot \sqrt{\sum_{i\,(I_i > 0)}^N \sigma_i^2 \cdot \big[(v_i - M_1)^2 - M_2^2\big]^2}](../_images/math/5c0c316e2a92a67e4e225f793ae633c4f7871df0.png)
where
is the rms noise in the channel.If
acfis provided, the uncertainty is propagated through the full spectral covariance rather than its diagonal — seecollapse_zeroth().- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Flux densities or brightness temperature array. Assumes that the first axis is the velocity axis.
rms (float) – Noise per pixel in same units as
data.acf (Optional[ndarray]) – Normalised spectral ACF. If
None(default), channels are assumed independent.
- Returns:
M2is the intensity weighted velocity dispersion with units ofvelax.dM2is the uncertainty ofM2in the same units.- Return type:
M2(ndarray),dM2(ndarray)
- bettermoments.methods.collapse_eighth(velax, data, rms)
Take the peak value along the provided axis. The uncertainty is the RMS noise of the image.
- Parameters:
velax (ndarray) – Velocity axis of the cube. Not needed.
data (ndarray) – Flux densities or brightness temperature array. Assumes that the first axis is the velocity axis.
rms (float) – Noise per pixel in same units as
data.
- Returns:
The peak value,
M8, and the associated uncertainty,dM8.- Return type:
M8(ndarray),dM8(ndarray)
- bettermoments.methods.collapse_ninth(velax, data, rms)
Take the velocity of the peak intensity along the provided axis. The uncertainty is half the channel width.
- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Flux densities or brightness temperature array. Assumes that the first axis is the velocity axis.
rms (float) – Noise per pixel in same units as
data.
- Returns:
The velocity value of the peak value,
M9, and the associated uncertainty,dM9.- Return type:
M9(ndarray),dM9(ndarray)
- bettermoments.methods.collapse_maximum(velax, data, rms)
A wrapper returning the result of both
bettermoments.collapse_cube.collapse_eighth()andbettermoments.collapse_cube.collapse_ninth().- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Flux densities or brightness temperature array. Assumes that the first axis is the velocity axis.
rms (float) – Noise per pixel in same units as
data.
- Returns:
The peak value,
M8, and the associated uncertainty,dM8. The velocity value of the peak value,M9, and the associated uncertainty,dM9.- Return type:
M8(ndarray),dM8(ndarray),M9(ndarray),dM9(ndarray)
Non-Traditional Methods
- bettermoments.methods.collapse_quadratic(velax, data, rms, acf=None)
Collapse the cube using the quadratic method presented in Teague & Foreman-Mackey (2018). Will return the line center,
v0, and the uncertainty on this,dv0, as well as the line peak,Fnu, and the uncertainty on that,dFnu. This provides the sub-channel precision ofbettermoments.collapse_cube.collapse_first()with the robustness to noise frombettermoments.collapse_cube.collapse_ninth().If
acfis provided, the uncertainties are propagated through the 3x3 spectral covariance sub-block centred on the peak channel rather than the diagonal — seecollapse_zeroth().- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Flux density or brightness temperature array. Assumes that the zeroth axis is the velocity axis.
rms (float) – Noise per pixel in same units as
data.acf (Optional[ndarray]) – Normalised spectral ACF. If
None(default), channels are assumed independent.
- Returns:
v0, the line center in the same units asvelaxwithdv0as the uncertainty onv0in the same units asvelax.Fnuis the line peak in the same units as thedatawith associated uncertainties,dFnu.- Return type:
v0(ndarray),dv0(ndarray),Fnu(ndarray),dFnu(ndarray)
- bettermoments.methods.collapse_width(velax, data, rms, acf=None)
Returns an effective width, a rescaled ratio of the integrated intensity and the line peak. For a Gaussian line profile this would be the Doppler width as the total intensity is given by,
where
and are the chanenl width and flux
density at the channel. If the line profile is Gaussian,
then equally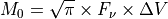
where
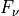 is the peak value of the line and
is the peak value of the line and 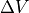 is
the Doppler width of the line. As
is
the Doppler width of the line. As 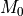 and are
readily calculated using
and are
readily calculated using
bettermoments.collapse_cube.collapse_zeroth()andbettermoments.collapse_cube.collapse_quadratic(), respectively, can calculated through 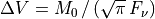 . This should be more robust against noise than
second moment maps.
. This should be more robust against noise than
second moment maps.- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Flux densities or brightness temperature array. Assumes that the first axis is the velocity axis.
rms (float) – Noise per pixel in same units as
data.
- Returns:
The effective velocity dispersion,
dVandddV, the associated uncertainty.- Return type:
dV(ndarray),ddV(ndarray)
- bettermoments.methods.collapse_percentiles(velax, data, rms)
Collapse the cube by taking intensity-weighted percentiles. This can be thought of as an extension to the first and second moments which are intensity weighted averages and standard deviations. The advantage here is that by looking at the 16th and 84th percentile individually, we learn something about the skewness of the line (i.e., red-shifted side compared to the blue-shifted side) without assuming a line profile.
- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Masked intensity or brightness temperature array. The first axis must be the velocity axis.
rms (float) – Noise per pixel in same units as
data.
- Returns:
- Eight ndarray values: the intensity-weighted median
(
wp50,dwp50), the blue- and red-shifted line widths (wpdVb,dwpdVb,wpdVr,dwpdVr), and the line center based on the center of the 16th and 84th percentile (wp1684,dwp1684).
- Return type:
tuple
(Higher Order) Gaussian Fits
- bettermoments.methods.collapse_gaussian(velax, data, rms, indices=None, ncpu=1, acf=None, **kwargs)
Collapse the cube by fitting a Gaussian line profile to each pixel. This function is a wrapper of collapse_analytical which provides more details about the arguments.
- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Maksed intensity or brightness temperature array. The first axis must be the velocity axis.
rms (float) – Noise per pixel in same units as
data.indices (Optional[list]) – A list of pixels described by
(y_idx, x_idx)tuples to fit. If none are provided, will fit all pixels.ncpu (Optional[int]) – Number of worker processes to use. Defaults to
1(serial). Set higher to parallelise across CPU cores.
- Returns:
- Six ndarray values: the Gaussian center (
gv0, dgv0), the Doppler line width (gdV,dgdV) and the line peak (gFnu,dgFnu).
- Six ndarray values: the Gaussian center (
- Return type:
tuple
- bettermoments.methods.collapse_gaussthick(velax, data, rms, indices=None, ncpu=1, acf=None, **kwargs)
Collapse the cube by fitting a Gaussian line profile with an optically thick core to each pixel. This function is a wrapper of collapse_analytical which provides more details about the arguments.
- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Maksed intensity or brightness temperature array. The first axis must be the velocity axis.
rms (float) – Noise per pixel in same units as
data.indices (Optional[list]) – A list of pixels described by
(y_idx, x_idx)tuples to fit. If none are provided, will fit all pixels.ncpu (Optional[int]) – Number of worker processes to use. Defaults to
1(serial). Set higher to parallelise across CPU cores.
- Returns:
- Eight ndarray values: the Gaussian center (
gtv0, dgtv0), the Doppler width (gtdV,dgtdV), the line peak (gtFnu,dgtFnu), and the effective optical depth (gttau,dgttau).
- Eight ndarray values: the Gaussian center (
- Return type:
tuple
- bettermoments.methods.collapse_gausshermite(velax, data, rms, indices=None, ncpu=1, acf=None, **kwargs)
Collapse the cube by fitting a Gaussian line profile with an optically thick core to each pixel. This function is a wrapper of collapse_analytical which provides more details about the arguments.
- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Maksed intensity or brightness temperature array. The first axis must be the velocity axis.
rms (float) – Noise per pixel in same units as
data.indices (Optional[list]) – A list of pixels described by
(y_idx, x_idx)tuples to fit. If none are provided, will fit all pixels.ncpu (Optional[int]) – Number of worker processes to use. Defaults to
1(serial). Set higher to parallelise across CPU cores.
- Returns:
- Ten ndarray values: the Gaussian center (
ghv0, dghv0), the line peak (ghFnu,dghFnu), the Doppler width (ghdV,dghdV), theh3asymmetry term (ghh3,dghh3) and theh4kurtosis term (ghh4,dghh4).
- Ten ndarray values: the Gaussian center (
- Return type:
tuple
- bettermoments.methods.collapse_doublegauss(velax, data, rms, indices=None, ncpu=1, acf=None, **kwargs)
Collapse the cube by fitting two Gaussian line profiles to each pixel. The first Gaussian component will be the peak of the two components. This function is a wrapper of collapse_analytical which provides more details about the arguments.
- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Maksed intensity or brightness temperature array. The first axis must be the velocity axis.
rms (float) – Noise per pixel in same units as
data.indices (Optional[list]) – A list of pixels described by
(y_idx, x_idx)tuples to fit. If none are provided, will fit all pixels.ncpu (Optional[int]) – Number of worker processes to use. Defaults to
1(serial). Set higher to parallelise across CPU cores.
- Returns:
- Twelve ndarray values: the primary Gaussian center
(
ggv0,dggv0), line peak (ggFnu,dggFnu) and Doppler width (ggdV,dggdV), followed by the same for the secondary component (ggv0b,dggv0b,ggFnub,dggFnub,ggdVb,dggdVb).
- Return type:
tuple
- bettermoments.methods.collapse_analytical(velax, data, rms, model_function, indices=None, ncpu=1, acf=None, **kwargs)
Collapse the cube by fitting an analytical form to each pixel, including the option to use an MCMC sampler which has been found to be more forgiving when it comes to noisy data. Parallelism is handled at the per-pixel level so work is distributed evenly across workers.
For more information on
kwargs, see thefit_spectrumdocumentation inmcmc_sampling.py.- Parameters:
velax (ndarray) – Velocity axis of the cube.
data (ndarray) – Masked intensity or brightness temperature array. The first axis must be the velocity axis.
rms (float) – Noise per pixel in same units as
data.model_function (str) – Name of the model function to fit to the data. Must be a function within
profiles.py.indices (Optional[list]) – A list of pixels described by
(y_idx, x_idx)tuples to fit. If none are provided, will fit all pixels.ncpu (Optional[int]) – Number of worker processes to use. Defaults to
1(serial execution with no pool overhead). Set to a higher value to parallelise across CPU cores.
- Returns:
- An array containing all the fits. The first
axis contains the mean and standard deviation of each posterior distribution.
- Return type:
results_array (ndarray)